Remove Duplicate Records Without Reference In SQL Server 2008
In this article I will demonstrate how to remove duplicate records from table without having primary key in SQL Server.
In this article I will demonstrate how to remove duplicate records from table without having primary key in SQL Server.
Once a table gets created without any primary key and user entered the same information twice. Duplicate data can generate many problems because there is no way to distinguish between the rows.
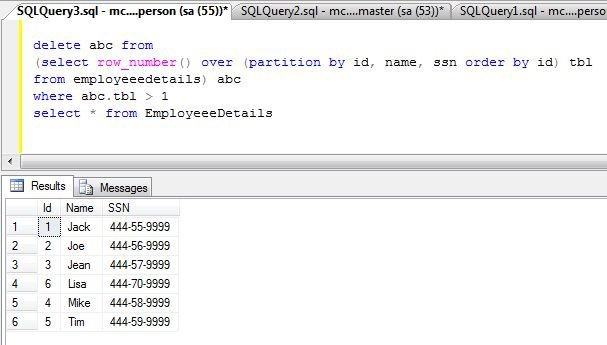
There is a way to remove duplicate records i.e. Use the row number to differentiate between duplicate data. set the first row number for an ID/SSN and delete the remaining.
Create a table named EmployeeDetails and add some records.
create table EmployeeeDetails
(
Id int,
Name varchar(10),
SSN varchar(12)
);
insert into EmployeeeDetails
select 1, 'Jack', '444-55-9999' union all
select 2, 'Joe', '444-56-9999' union all
select 3, 'Jean', '444-57-9999' union all
select 5, 'Tim', '444-59-9999' union all
select 6, 'Lisa', '444-70-9999' union all
select 1, 'Jack', '444-55-9999' union all
select 4, 'Mike', '444-58-9999' union all
select 5, 'Tim', '444-59-9999' union all
select 6 ,'Lisa', '444-70-9999' union all
select 5, 'Tim', '444-59-9999'
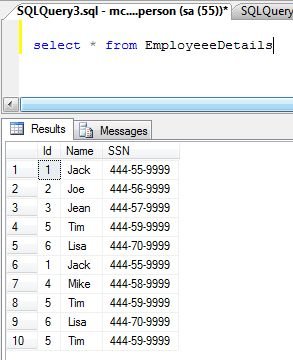
Select all records from table.
To delete the duplicate records uUse the row number to differentiate between duplicate data., write following SQL statement: