In this article I will demonstrate how to remove duplicate records in SQL Server. In a correlated subquery, the first outer query is executed, this result is used by an inner sub-query for its execution, then result is again used by outer query to get final result.
Create Table
CREATE TABLE [dbo].[Student1Details](
[ID] [int] NOT NULL,
[Name] [varchar](50) NULL,
[Branch] [varchar](10) NULL,
[Location] [varchar](10) NULL,
CONSTRAINT [PK_Student1] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
) ON [PRIMARY]
Insert some values
INSERT INTO Student1Details
SELECT 1, 'Nitin', 'CS','IND' UNION ALL
SELECT 2, 'Ravi', 'EI','ENG' UNION ALL
SELECT 3, 'Tim', 'ME','US' UNION ALL
SELECT 4, 'Rick', 'ME','IND' UNION ALL
SELECT 5, 'Rakesh', 'CS','ABD' UNION ALL
SELECT 6, 'Tarun', 'ME','IND' UNION ALL
SELECT 7,'Raushan','IT','IND' UNION ALL
SELECT 8,'Aman','EC','US'
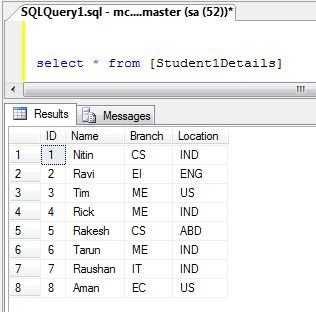
SELECT * FROM Student1Details
Student1Details Table
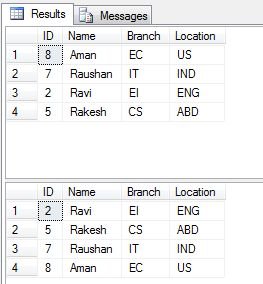
Removing Duplicate Records
select * from Student1Details S1
where S1.ID=(select max(ID) from Student1Details S2
where S1.Location=S2.Location)
GO
--Deleting Duplicate Records
delete Student1Details where ID< (select max(ID) from Student1Details S2
where S2.Location = Student1Details.Location)
GO
SELECT * FROM Student1Details
GO
Output: